.avif)
Antes de la década de 1980, las computadoras eran en gran medida criaturas antisociales. Vivían aislados, sin hablar ni interactuar entre sí en absoluto. La información que albergaban nunca salía de los confines del hardware que la almacenaba, y «compartir» datos consistía en llevar físicamente una computadora a otra ubicación. Si bien los ordenadores que antes estaban conectados a la red eran máquinas maravillosas para su época, su silencio imponía una grave limitación a su utilidad.
Una empresa llamada Apollo Computer, fundada en 1980, se propuso cambiar esta situación. Apollo, uno de los primeros innovadores en este ámbito, sentó las bases para una era de rápido crecimiento de las redes informáticas al crear el Sistema de Computación en Red (NCS), un conjunto de herramientas y protocolos que ayudaban a los desarrolladores de software a crear aplicaciones «distribuidas» a través de las cuales las computadoras de la misma red podían compartir datos. Uno de los estándares que estableció el NCS fue un sistema para etiquetar la información para que se reconociera cuando se compartía entre máquinas, y así nació el concepto del UUID.
¿Qué es un UUID?
Un identificador único universal (UUID) es una etiqueta alfanumérica de 36 caracteres que se utiliza para proporcionar una identidad única a cualquier recopilación de información dentro de un sistema informático. Debido a su probabilidad extremadamente baja de duplicación, los UUID son una herramienta ampliamente adoptada para proporcionar identidades persistentes y únicas a prácticamente todos los tipos de datos imaginables.
Las especificaciones y el formato de los UUID han evolucionado desde esta primera versión del NCS, pero las características principales siguen siendo las mismas: los UUID son fáciles de generar, de verdad único, y es fácil de soportar y analizar para las aplicaciones. Por estas razones, se adoptan ampliamente en todas las aplicaciones, desde las redes sociales hasta los almacenes de datos.
Versiones de UUID
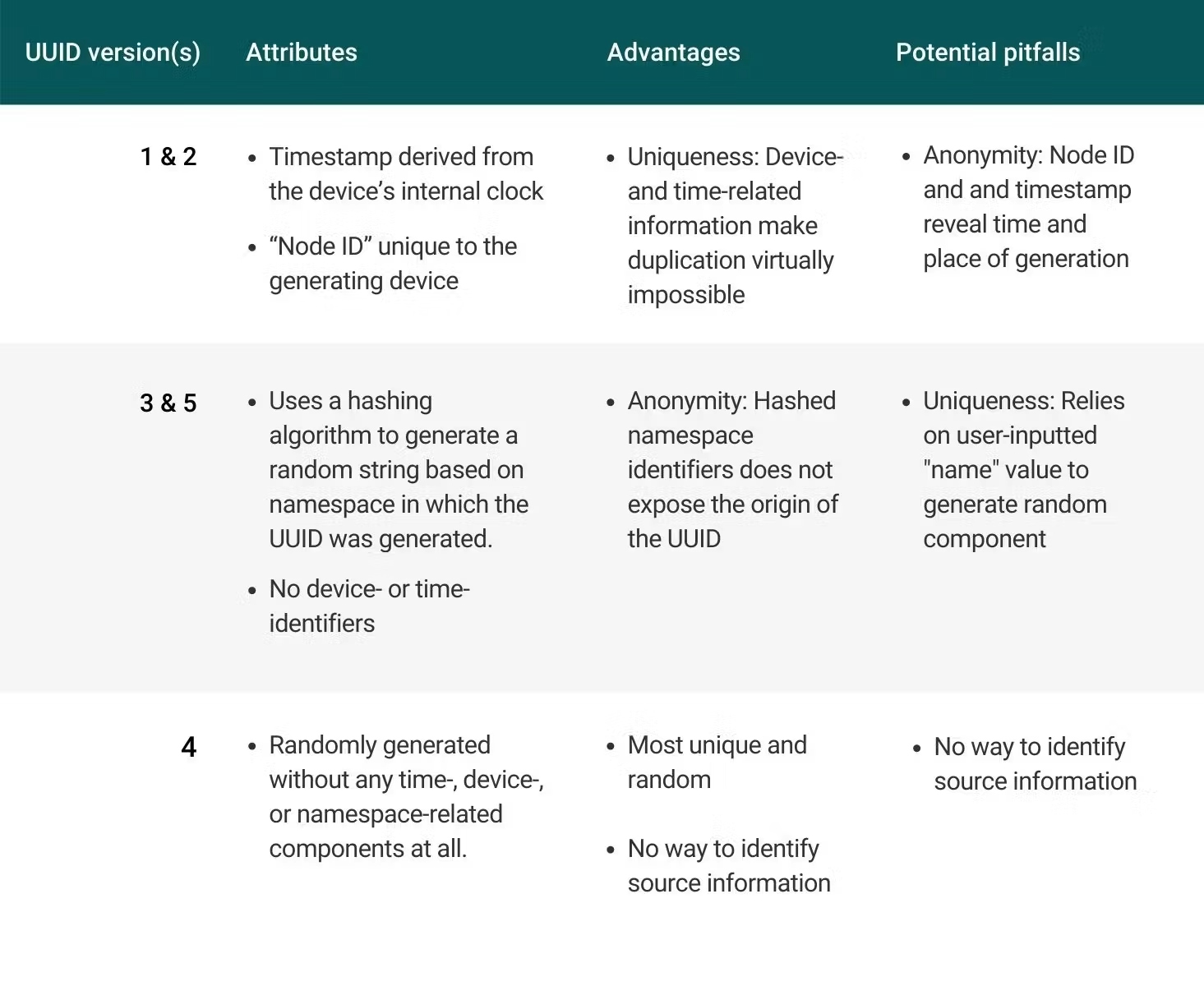
Hoy en día hay cinco versiones diferentes de UUID. Cada versión tiene puntos fuertes ligeramente diferentes y, por lo tanto, puede ser adecuada para diferentes casos de uso. Este es un desglose de las principales diferencias y características de las diferentes versiones del UUID:
Versiones 1 y 2
Los UUID de la versión 1 a veces se denominan «basados en el tiempo», ya que incorporan la fecha y hora en la que se generaron. Además de la fecha y hora, la sección final de estos UUID se deriva de la dirección del controlador de acceso al medio (MAC) del dispositivo generador. Constan de cinco secciones separadas por guiones:
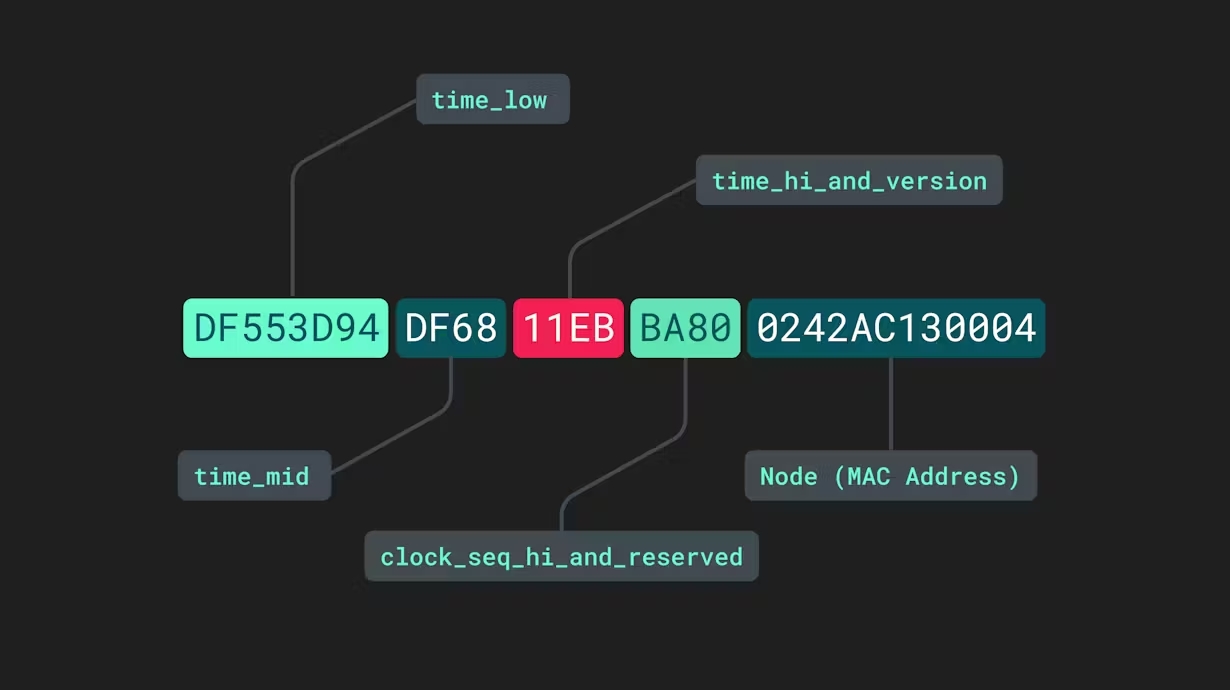
El tiempo_bajo, time_mid, y time_high_y_version las secciones se refieren a las marcas de tiempo bajas, medias y altas dentro de la información de fecha y hora actual. La cuarta sección, clock_seq_hi_y_reserved, es un nombre un tanto inapropiado. Si bien la «secuencia de reloj» puede parecer otro valor tomado de otro proceso interno, de hecho es solo un valor de 16 bits generado aleatoriamente que ayuda a disminuir la probabilidad de que dos UUID de la versión 1 sean idénticos. Por último, los últimos 12 caracteres se toman de la dirección MAC del dispositivo.
La concatenación de la fecha y hora con la dirección MAC del dispositivo en una sola etiqueta produce una combinación de letras y números que es prácticamente imposible de replicar. Para que dos UUID v1 o UUID v2 separados sean idénticos, tendrían que ser producidos por el mismo dispositivo exactamente al mismo tiempo. Agregar la cadena adicional generada aleatoriamente hace que la probabilidad de duplicación o «colisión» sea infinitesimalmente pequeña.
En la mayoría de los casos de uso, la información identificable de la hora y el dispositivo dentro del UUID no es un inconveniente. De hecho, dentro de un sistema distribuido, esto puede ser una ventaja: elimina la necesidad de designar una sola autoridad para generar identificadores y permite ver qué nodos de la red generaron los UUID. Sin embargo, en situaciones en las que es importante que los objetos que está identificando no estén vinculados al hardware físico en el que se creó su ID, es probable que sea mejor optar por las versiones 3, 4 o 5.
Versión 2
La única diferencia en la versión 2 es que parte de la información de fecha y hora que estaría en un UUID v1 se reemplaza por un número de dominio local. Si bien esto puede resultar útil en determinadas situaciones, limita la singularidad del UUID y plantea ciertos problemas de privacidad. Por esta razón, los UUID v2 no se utilizan ampliamente.
Versiones 3 y 5
Al igual que las versiones 1 y 2, los UUID de las versiones 3 y 5 tampoco son aleatorios en el sentido de que utilizan la información ingresada para generar un valor alfanumérico de 32 caracteres. Sin embargo, estas versiones se crean basándose en datos de «espacio de nombres» y «nombre», en lugar de en valores relacionados con el tiempo y los nodos. El espacio de nombres la entrada es en sí misma un UUID que indica el entorno de la aplicación en el que se utilizará el valor. El nombre El valor a menudo indica para qué se utilizará el ID, es decir, un nombre de usuario o de cuenta, y con frecuencia lo proporciona directamente (o de forma dinámica) el desarrollador que genera los ID dentro de una aplicación.
A continuación, las entradas de nombre y espacio de nombres se ejecutan mediante un algoritmo de hash para generar el UUID. La principal diferencia entre los UUID v3 y v5 es el algoritmo de hash utilizado para generarlos: la v3 usa MD5, y v5 usa SHA-1. Cuando se utiliza un paquete o una biblioteca para generar UUID dentro de una aplicación, los valores de nombre y espacio de nombres suelen pasarse como argumentos a un método que genera los UUID de estas dos versiones. Estos paquetes también suelen proporcionar formas de acceder dinámicamente a los valores de página de nombres de uso frecuente, como DNS y URL. Por ejemplo, crear un UUID v3 con Biblioteca UUID de Python se vería así:
import uuid
UUID3 = uuid.uuid3(uuid.NAMESPACE_URL, "item/143462")
print("Here is a version 3 UUID! ", UUID3)
# Output: Here is a version 3 UUID! fbf825a3-79e0-3877-b486-cb53da71d414Versión 4
Los UUID de la versión 4 son probablemente los más fáciles de entender y quizás también los más utilizados. Estos UUID son simplemente valores generados aleatoriamente (derivados de un generador criptográficamente seguro) que no contienen ningún espacio de nombres, dispositivo o información basada en el tiempo.
Se ven así: adbbf6bd-1746-4545-a3ce-8b153a7a31b2
El único carácter no aleatorio de este valor es el «4» en la primera posición de la tercera sección (después del segundo guión), lo que indica que se trata de un UUID v4. Aparte de eso, todos los demás caracteres son solo un número aleatorio del 0 al 9, o una letra minúscula de la a a la z.
Este es un resumen de los atributos, las posibles ventajas y los posibles inconvenientes de cada versión del UUID:
¿Cómo se generan los UUID en las aplicaciones?
Si bien es posible que te sientas tentado a «lanzar tu propia» función de UUID y usarla en una aplicación, esta no es la mejor práctica. El Grupo de trabajo sobre ingeniería de Internet—la organización que publica los estándares en torno a los UUID— ha establecido ciertas pautas sobre el nivel de singularidad que deben mantener los UUID. Y si bien es posible escribir una función simple en el idioma de su elección que devuelva UUID compatibles (cuyos criterios se describen) aquí, por si tiene curiosidad), probablemente no querrá mantener ese código para asegurarse de que su salida siga cumpliendo con los requisitos.
Afortunadamente, hay varias bibliotecas bien mantenidas que puedes usar y que se encargarán de esta tarea por ti. En JavaScript, por ejemplo, puedes usar el paquete uuid npm. Tras ejecutar `npm install uuid`, puedes especificar qué versión de UUID quieres usar en la declaración de importación:
`importar {v1 como uuidv1} desde 'uuid'; `
Crear un UUID de la versión 1 sería entonces tan simple como llamar a `uuidv1 () `como una función, o pasar `opciones` adicionales especificando los datos de nodo y hora:
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678,
};
uuidv1(v1options);En un entorno de Python, el Biblioteca UUID La que se muestra arriba es una herramienta en espera, aunque muchos desarrolladores han creado otras opciones para casos de uso específicos. A menos que su aplicación o base de datos exija un uso matizado de los UUID que un paquete popular no pueda atender, la mejor práctica es utilizar una biblioteca bien mantenida y actualizada con regularidad para garantizar que las tecnologías criptográficas subyacentes que crean sus identificadores sigan siendo las más modernas.
Casos de uso de UUID
Los UUID son apropiados para una amplia variedad de casos de uso en diferentes tipos de sistemas, ya que sus universal la naturaleza significa que pueden generarse en cualquier lugar dentro de una red. Esto elimina la necesidad de designar esta tarea a un único nodo del sistema. Estos son algunos ejemplos comunes de cómo se usan los UUID en la naturaleza:
Aplicaciones web
Dentro de una aplicación web, los UUID se pueden generar en la interfaz de la aplicación sin necesidad de llamar a un servidor o base de datos. Esto hace que los UUID sean ideales para etiquetar objetos de datos relacionados con la administración del estado, como los ID de usuario o de sesión.
Sistemas de análisis
Es probable que cualquier sistema de aplicaciones de terceros que se integre en una aplicación web o móvil, como herramientas de marketing, análisis y publicidad, necesite generar identificadores únicos. Por ejemplo, una empresa de publicidad que quiera identificar las impresiones, los clics y otros eventos de una sesión de usuario único podría generar un UUID al principio de la sesión y, a continuación, asociar eventos individuales a este identificador único.
Sistemas de bases de datos
En los sistemas de bases de datos distribuidas, los UUID pueden resultar muy útiles para dividir tablas grandes y almacenarlas en varios servidores. A cada parte de la misma tabla se le puede asignar el mismo UUID, lo que hace que los datos sean identificables como un conjunto único al realizar operaciones de lectura/escritura.
¿Está interesado en el tema de la identidad del usuario y el mantenimiento de la identificación de datos entre sistemas? Descubra cómo funcionan las plataformas de datos de clientes ayudar a los equipos de ingeniería simplifique la recopilación de datos multicanal, agilice la transformación y la entrega de datos y aborde otros desafíos técnicos del ecosistema de datos moderno.
Nota: Si alguna vez necesitas determinar la probabilidad de una colisión con un UUID, o si la teoría de la probabilidad es algo que te alegra el corazón, puedes usar el Problema de cumpleaños.



.png)

