.avif)
Vor den 1980er Jahren waren Computer größtenteils antisoziale Wesen. Sie lebten isoliert und sprachen oder interagierten überhaupt nicht miteinander. Die Informationen, die sie gespeichert hatten, haben nie die Grenzen der Hardware verlassen, auf der sie gespeichert waren, und Daten zu „teilen“ bedeutete, einen Computer physisch an einen anderen Ort zu bringen. Obwohl vorvernetzte Computer für ihre Zeit wundersame Maschinen waren, schränkte ihre Stummheit ihren Nutzen stark ein.
Ein 1980 gegründetes Unternehmen namens Apollo Computer wollte dies ändern. Apollo, einer der ersten Innovatoren in diesem Bereich, legte den Grundstein für eine Ära des schnellen Wachstums von Computernetzwerken, indem es das Networked Computing System (NCS) entwickelte, eine Reihe von Tools und Protokollen, die Softwareentwicklern dabei halfen, „verteilte“ Anwendungen zu entwickeln, über die Computer im selben Netzwerk Daten austauschen konnten. Ein Standard, den das NCS festlegte, war ein System zur Kennzeichnung von Informationen, damit diese erkannt werden konnten, wenn sie von Maschinen geteilt wurden, und so war das Konzept der UUID geboren.
Was ist eine UUID?
Ein Universally Unique Identifier (UUID) ist ein 36-stelliges alphanumerisches Etikett, das verwendet wird, um jeder Sammlung von Informationen innerhalb eines Computersystems eine eindeutige Identität zu verleihen. Aufgrund ihrer extrem geringen Wahrscheinlichkeit einer Duplizierung sind UUIDs ein weit verbreitetes Instrument, um praktisch allen erdenklichen Datentypen dauerhafte und eindeutige Identitäten zu verleihen.
Die Spezifikationen und das Format von UUIDs haben sich seit dieser frühesten Iteration im NCS weiterentwickelt, aber die Kernfunktionen sind dieselben geblieben: UUIDs sind wirklich einfach zu generieren einzigartigund für Anwendungen einfach zu unterstützen und zu analysieren. Aus diesen Gründen werden sie in vielen Anwendungen, von sozialen Netzwerken bis hin zu Data Warehouses, eingesetzt.
UUID-Versionen
Heute gibt es fünf verschiedene UUID-Versionen. Jede Version hat leicht unterschiedliche Stärken und kann daher für unterschiedliche Anwendungsfälle geeignet sein. Hier finden Sie eine Aufschlüsselung der wichtigsten Unterschiede und Merkmale der verschiedenen UUID-Versionen:
Version 1 und 2
UUIDs der Version 1 werden manchmal als „zeitbasiert“ bezeichnet, da sie das Datum und die Uhrzeit enthalten, zu der sie generiert wurden. Zusätzlich zur Datetime wird der letzte Abschnitt dieser UUIDs von der Media Access Controller (MAC) -Adresse des generierenden Geräts abgeleitet. Sie bestehen aus fünf separaten Abschnitten, die durch Bindestriche getrennt sind:
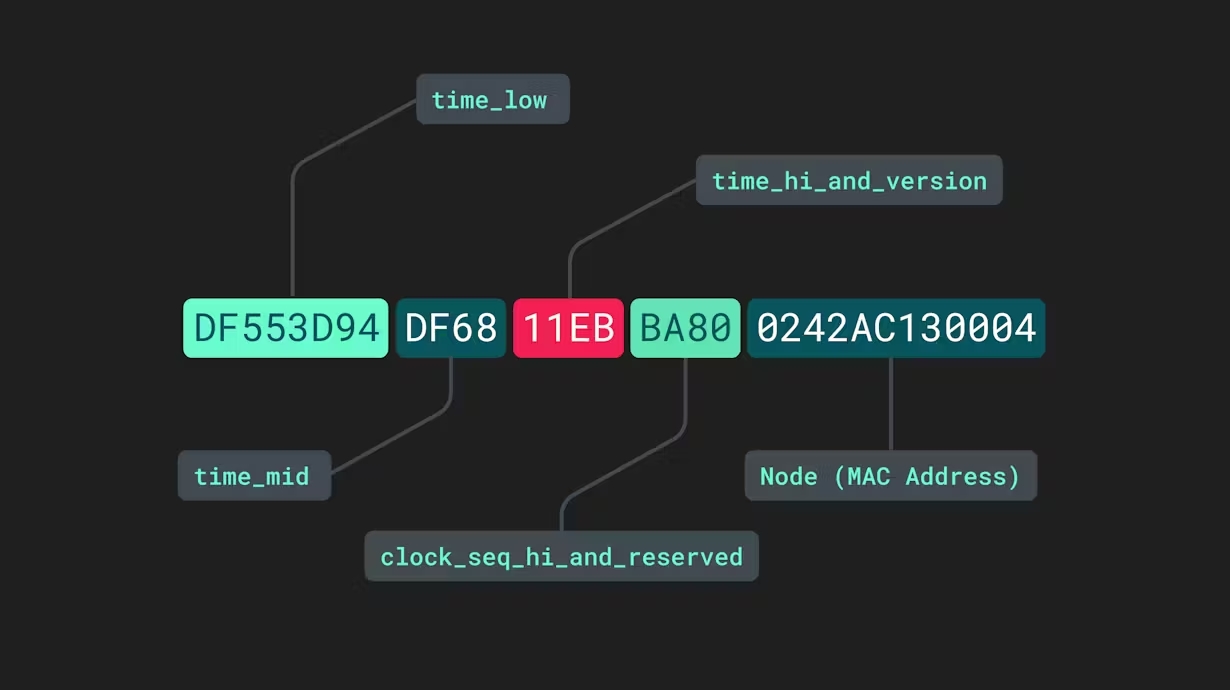
Das time_low, time_mid, und time_high_and_version Abschnitte beziehen sich auf die niedrigen, mittleren und hohen Zeitstempel in den aktuellen Datetime-Informationen. Der vierte Abschnitt, clock_seq_hi_and_reserved, ist eine etwas falsche Bezeichnung. Obwohl „Taktsequenz“ wie ein anderer Wert aus einem anderen internen Prozess klingt, handelt es sich in Wirklichkeit nur um einen zufällig generierten 16-Bit-Wert, der dazu beiträgt, die Wahrscheinlichkeit zu verringern, dass zwei v1-UUIDs jemals identisch sein könnten. Schließlich werden die letzten 12 Zeichen von der MAC-Adresse des Geräts übernommen.
Wenn Sie das Datum und die Uhrzeit mit der MAC-Adresse des Geräts zu einem einzigen Etikett verketten, entsteht eine Kombination aus Buchstaben und Zahlen, die praktisch nicht repliziert werden kann. Damit zwei separate UUID v1 oder UUID v2s identisch sind, müssten sie von demselben Gerät genau zur gleichen Zeit erzeugt werden. Das Hinzufügen der zusätzlichen zufällig generierten Zeichenfolge macht die Wahrscheinlichkeit einer Duplikation oder „Kollision“ infinitesimal klein.
In den meisten Anwendungsfällen sind die identifizierbaren Zeit- und Geräteinformationen innerhalb der UUID kein Nachteil. In einem verteilten System kann dies sogar von Vorteil sein — es entfällt die Notwendigkeit, eine einzige Autorität zur Generierung von Identifikatoren zu benennen, und Sie können sehen, welche Knoten innerhalb des Netzwerks UUIDs generiert haben. In Situationen, in denen es wichtig ist, dass die Objekte, die Sie identifizieren, nicht an die physische Hardware gebunden sind, auf der ihre ID erstellt wurde, ist es jedoch wahrscheinlich am besten, sich für die Versionen 3, 4 oder 5 zu entscheiden.
Variante 2
Der einzige Unterschied in Version 2 besteht darin, dass ein Teil der Datetime-Informationen, die in einer v1-UUID enthalten wären, durch eine lokale Domainnummer ersetzt wird. Dies kann zwar in bestimmten Situationen nützlich sein, schränkt jedoch die Eindeutigkeit der UUID ein und wirft bestimmte Datenschutzbedenken auf. Aus diesem Grund werden v2-UUIDs nicht häufig verwendet.
Versionen 3 und 5
Wie die Versionen 1 und 2 sind auch die UUIDs der Versionen 3 und 5 nicht zufällig in dem Sinne, dass sie eingegebene Informationen verwenden, um einen 32-stelligen alphanumerischen Wert zu generieren. Diese Versionen werden jedoch auf der Grundlage von „Namespace“ - und „Name“ -Daten und nicht auf zeit- und knotenbezogenen Werten erstellt. Das Namensraum input ist selbst eine UUID, die die Anwendungsumgebung bezeichnet, in der der Wert verwendet wird. Das Name Ein Wert gibt oft an, wofür die ID verwendet wird, z. B. einen Benutzer- oder Kontonamen, und wird oft direkt (oder dynamisch) vom Entwickler bereitgestellt, der die IDs innerhalb einer Anwendung generiert.
Namespace- und Namenseingaben werden dann einem Hashing-Algorithmus unterzogen, um die UUID zu generieren. Der Hauptunterschied zwischen v3- und v5-UUIDs ist der Hashing-Algorithmus, der verwendet wird, um sie zu generieren — v3-UIDs verwendet MD5, und v5 verwendet SHA-1. Wenn ein Paket oder eine Bibliothek verwendet wird, um UUIDs innerhalb einer Anwendung zu generieren, werden Namespace- und Namenswerte häufig als Argumente an eine Methode übergeben, die UUIDs dieser beiden Versionen ausgibt. Diese Pakete bieten auch häufig Möglichkeiten, dynamisch auf häufig verwendete Namespage-Werte wie DNS und URL zuzugreifen. Erstellen Sie beispielsweise eine v3-UUID mit dem Python-UUID-Bibliothek würde so aussehen:
import uuid
UUID3 = uuid.uuid3(uuid.NAMESPACE_URL, "item/143462")
print("Here is a version 3 UUID! ", UUID3)
# Output: Here is a version 3 UUID! fbf825a3-79e0-3877-b486-cb53da71d414Ausführung 4
UUIDs der Version 4 sind wahrscheinlich am einfachsten zu verstehen und vielleicht auch am häufigsten verwendet. Diese UUIDs sind einfach zufällig generierte Werte (abgeleitet von einem kryptografisch sicheren Generator), die keine Namespace-, Geräte- oder zeitbasierten Informationen enthalten.
Sie sehen so aus: adbbf6bd-1746-4545-a3ce-8b153a7a31b2
Das einzige nicht zufällige Zeichen in diesem Wert ist die „4“ an der ersten Position des dritten Abschnitts (nach dem zweiten Bindestrich), was darauf hinweist, dass es sich um eine v4-UUID handelt. Davon abgesehen ist jedes andere Zeichen nur eine Zufallszahl von 0-9 oder ein Kleinbuchstabe von a-z.
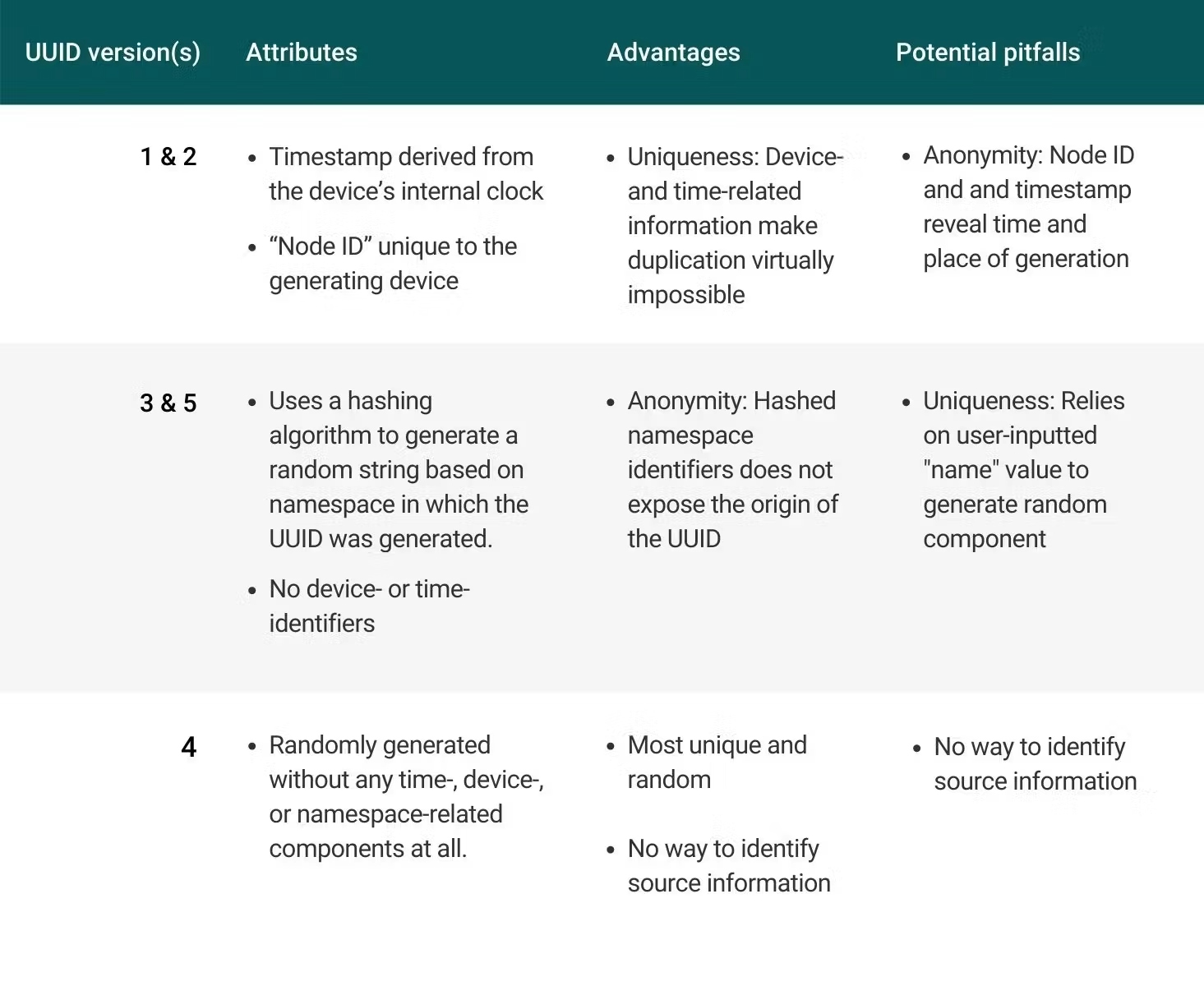
Hier ist eine Zusammenfassung der Attribute, möglichen Vorteile und potenziellen Fallstricke jeder UUID-Version:
Wie generiert man UUIDs in Anwendungen?
Sie könnten zwar versucht sein, Ihre eigene UUID-Funktion zu „rollen“ und sie in einer Anwendung zu verwenden, aber dies ist nicht die beste Vorgehensweise. Das Arbeitsgruppe Internettechnik——die Organisation, die die Standards rund um UUIDs veröffentlicht——hat bestimmte Richtlinien für den Grad der Eindeutigkeit festgelegt, den UUIDs einhalten müssen. Und obwohl es möglich ist, eine einfache Funktion in der Sprache Ihrer Wahl zu schreiben, die konforme UUIDs zurückgibt (deren Kriterien beschrieben sind) hier, falls Sie neugierig sind), werden Sie diesen Code wahrscheinlich nicht pflegen wollen, um sicherzustellen, dass seine Ausgabe weiterhin den Anforderungen entspricht.
Zum Glück gibt es mehrere gut gepflegte Bibliotheken, die Sie verwenden können und die diese Aufgabe für Sie erledigen. In JavaScript können Sie beispielsweise die uuid npm-Paket. Nachdem Sie `npm install uuid` ausgeführt haben, können Sie in der Import-Anweisung angeben, welche UUID-Version Sie verwenden möchten:
`importiere {v1 als uuidv1} aus 'uuid'; `
Das Erstellen einer UUID der Version 1 wäre dann so einfach, wie `uuidv1 () `als Funktion aufzurufen oder zusätzliche `Optionen` zu übergeben, die Knoten- und Zeitdaten angeben:
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678,
};
uuidv1(v1options);In einer Python-Umgebung ist der UUID-Bibliothek Das oben gezeigte ist ein Standby-Tool, obwohl viele Entwickler andere Optionen für bestimmte Anwendungsfälle entwickelt haben. Sofern Ihre Anwendung oder Datenbank keine differenzierte Verwendung von UUIDs erfordert, die ein gängiges Paket nicht verarbeiten kann, empfiehlt es sich, eine gut gewartete und regelmäßig aktualisierte Bibliothek zu verwenden, um sicherzustellen, dass die zugrunde liegenden kryptografischen Technologien, die Ihre Identifikatoren erstellen, auf dem neuesten Stand der Technik sind.
Anwendungsfälle für UUIDs
UUIDs eignen sich für eine Vielzahl von Anwendungsfällen in verschiedenen Systemtypen, da ihre universell Die Natur bedeutet, dass sie überall innerhalb eines Netzwerks generiert werden können. Dadurch entfällt die Notwendigkeit, diese Aufgabe einem einzelnen Systemknoten zuzuweisen. Hier sind einige gängige Beispiele dafür, wie UUIDs in freier Wildbahn verwendet werden:
Webanwendungen
Innerhalb einer Webanwendung können UUIDs im Frontend der App generiert werden, ohne dass ein Aufruf eines Servers oder einer Datenbank erforderlich ist. Dies macht UUIDs ideal für die Kennzeichnung von Datenobjekten im Zusammenhang mit der Zustandsverwaltung, wie z. B. Benutzer- oder Sitzungs-IDs.
Analytische Systeme
Jedes Anwendungssystem von Drittanbietern, das in eine Web- oder Mobilanwendung integriert wird, z. B. Marketing-, Analyse- und Werbetools, muss wahrscheinlich eindeutige Identifikatoren generieren. Beispielsweise könnte ein Werbeunternehmen, das die Impressionen, Klicks und andere Ereignisse innerhalb einer einzelnen Benutzersitzung identifizieren möchte, zu Beginn einer Sitzung eine UUID generieren und dann einzelne Ereignisse dieser einzelnen ID zuordnen.
Datenbanksysteme
In verteilten Datenbanksystemen können UUIDs sehr nützlich sein, um große Tabellen aufzuteilen und auf mehreren Servern zu speichern. Jedem Teil derselben Tabelle kann dieselbe UUID zugewiesen werden, wodurch die Daten bei Lese-/Schreiboperationen als ein einziger Satz identifizierbar sind.
Interessieren Sie sich für das Thema Benutzeridentität und Pflege der systemübergreifenden Datenidentifikation? Erfahren Sie, wie Customer Data Platforms helfen Sie Ingenieurteams Vereinfachen Sie die kanalübergreifende Datenerfassung, optimieren Sie die Datentransformation und -bereitstellung und bewältigen Sie andere technische Herausforderungen des modernen Datenökosystems.
Hinweis: Wenn Sie jemals die Wahrscheinlichkeit einer UUID-Kollision bestimmen müssen oder die Wahrscheinlichkeitstheorie nur etwas ist, das Ihrem Herzen Freude bereitet, können Sie die Geburtstagsproblem.



.png)

