.avif)
Avant les années 1980, les ordinateurs étaient en grande partie des créatures antisociales. Ils vivaient isolés, sans se parler ni interagir du tout. Les informations qu'ils hébergeaient ne quittaient jamais les limites du matériel qui les stockait, et « partager » des données revenait à déplacer physiquement un ordinateur vers un autre emplacement. Même si les ordinateurs préconnectés étaient des machines extraordinaires pour l'époque, leur caractère devait limiter considérablement leur utilité.
Une société appelée Apollo Computer, fondée en 1980, a décidé de changer cela. Apollo, l'un des premiers innovateurs dans ce domaine, a jeté les bases d'une ère de croissance rapide des réseaux informatiques en créant le système informatique en réseau (NCS), un ensemble d'outils et de protocoles qui ont aidé les développeurs de logiciels à créer des applications « distribuées » grâce auxquelles les ordinateurs d'un même réseau pouvaient partager des données. L'une des normes définies par le NCS était un système d'étiquetage des informations afin qu'elles soient reconnues lorsqu'elles étaient partagées entre les machines. C'est ainsi qu'est né le concept de l'UUID.
Qu'est-ce qu'un UUID ?
Un identifiant unique universel (UUID) est une étiquette alphanumérique à 36 caractères utilisée pour fournir une identité unique à toute collection d'informations au sein d'un système informatique. En raison de leur très faible probabilité de duplication, les UUID sont un outil largement adopté pour donner des identités persistantes et uniques à pratiquement tous les types de données imaginables.
Les spécifications et le format des UUID ont évolué depuis cette première itération du NCS, mais les fonctionnalités de base restent les mêmes : les UUID sont vraiment faciles à générer unique, et simple à prendre en charge et à analyser pour les applications. Pour ces raisons, ils sont largement adoptés dans toutes les applications, des réseaux sociaux aux entrepôts de données.
Versions de l'UUID
Il existe aujourd'hui cinq versions différentes de l'UUID. Chaque version présente des atouts légèrement différents et peut donc être adaptée à différents cas d'utilisation. Voici un aperçu des principales différences et caractéristiques des différentes versions de l'UUID :
Versions 1 et 2
Les UUID de version 1 sont parfois considérés comme étant « temporels » car ils intègrent la date et l'heure auxquelles ils ont été générés. Outre la date et l'heure, la dernière section de ces UUID est dérivée de l'adresse MAC (Media Access Controller) du périphérique générateur. Ils se composent de cinq sections distinctes séparées par des tirets :
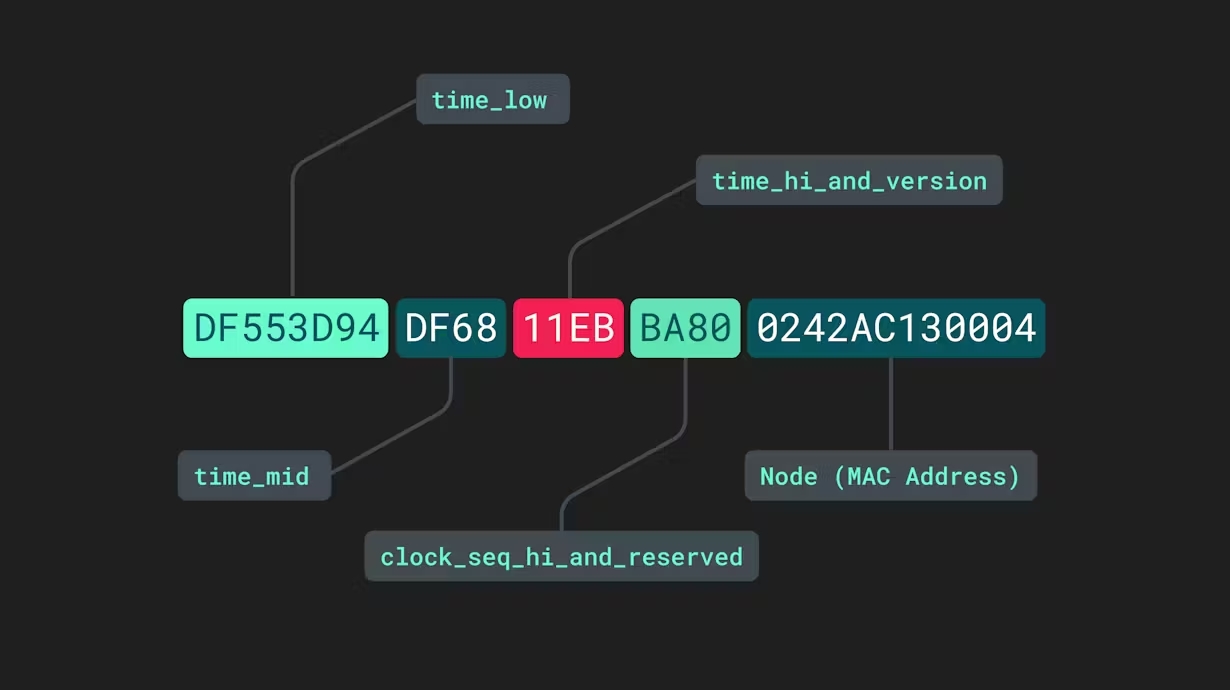
Le time_low, time_mid, et horaire_et_version les sections concernent les horodatages bas, moyens et élevés contenus dans les informations de date et d'heure actuelles. La quatrième section, clock_seq_hi_and_reserved, est un peu impropre. Bien que la « séquence d'horloge » puisse ressembler à une autre valeur provenant d'un autre processus interne, il s'agit en fait d'une valeur 16 bits générée de manière aléatoire qui contribue à réduire la probabilité que deux UUID v1 soient identiques. Enfin, les 12 derniers caractères sont extraits de l'adresse MAC de l'appareil.
La concaténation de la date et de l'heure avec l'adresse MAC de l'appareil en une seule étiquette produit une combinaison de lettres et de chiffres pratiquement impossible à reproduire. Pour que deux UUID v1 ou UUID v2 distincts soient identiques, ils devraient être produits par le même appareil exactement au même moment. L'ajout de la chaîne supplémentaire générée de manière aléatoire réduit infiniment la probabilité de duplication, ou « collision ».
Dans la plupart des cas d'utilisation, l'heure identifiable et les informations relatives à l'appareil dans l'UUID ne constituent pas un inconvénient. En fait, dans un système distribué, cela peut être un avantage : cela élimine la nécessité de désigner une autorité unique pour générer des identifiants et vous permet de voir quels nœuds du réseau ont généré des UUID. Dans les situations où il est important que les objets que vous identifiez ne soient pas liés au matériel physique sur lequel leur identifiant a été créé, il est préférable d'opter pour les versions 3, 4 ou 5.
Version 2
La seule différence dans la version 2 est qu'une partie des informations de date et d'heure qui se trouveraient dans un UUID v1 est remplacée par un numéro de domaine local. Bien que cela puisse être utile dans certaines situations, cela limite le caractère unique de l'UUID et soulève certaines préoccupations en matière de confidentialité. Pour cette raison, les UUID v2 ne sont pas largement utilisés.
Versions 3 et 5
Comme les versions 1 et 2, les UUID des versions 3 et 5 ne sont pas aléatoires en ce sens qu'ils utilisent les informations saisies pour générer une valeur alphanumérique de 32 caractères. Cependant, ces versions sont créées sur la base de données « espace de noms » et « nom » plutôt que sur des valeurs liées au temps et aux nœuds. Le namesspace input est lui-même un UUID qui indique l'environnement d'application dans lequel la valeur sera utilisée. Le nom value indique souvent à quoi l'identifiant sera utilisé, c'est-à-dire un nom d'utilisateur ou de compte, et est souvent fournie directement (ou dynamiquement) par le développeur qui génère les identifiants dans une application.
Les entrées d'espace de noms et de noms sont ensuite exécutées via un algorithme de hachage pour générer l'UUID. La principale différence entre les UUID v3 et v5 réside dans l'algorithme de hachage utilisé pour les générer. La v3 utilise MD5, et la version 5 utilise SHA-1. Lorsque vous utilisez un package ou une bibliothèque pour générer des UUID dans une application, les valeurs d'espace de noms et de noms sont souvent transmises en tant qu'arguments à une méthode qui génère des UUID de ces deux versions. Ces packages fournissent également généralement des moyens d'accéder dynamiquement aux valeurs de page de noms fréquemment utilisées, telles que le DNS et l'URL. Par exemple, créer un UUID v3 avec Python UUID library ressemblerait à ceci :
import uuid
UUID3 = uuid.uuid3(uuid.NAMESPACE_URL, "item/143462")
print("Here is a version 3 UUID! ", UUID3)
# Output: Here is a version 3 UUID! fbf825a3-79e0-3877-b486-cb53da71d414Version 4
Les UUID de la version 4 sont probablement les plus simples à comprendre, et peut-être aussi les plus fréquemment utilisés. Ces UUID sont simplement des valeurs générées de manière aléatoire (dérivées d'un générateur cryptographiquement sécurisé) qui ne contiennent aucun espace de noms, aucun périphérique ou aucune information temporelle.
Ils ressemblent à ceci : adbbf6bd-1746-4545-a3ce-8b153a7a31b2
Le seul caractère non aléatoire de cette valeur est le « 4 » en première position de la troisième section (après le deuxième tiret), ce qui indique qu'il s'agit d'un UUID v4. En dehors de cela, tous les autres caractères sont juste un nombre aléatoire de 0 à 9, ou une lettre minuscule de A à Z.
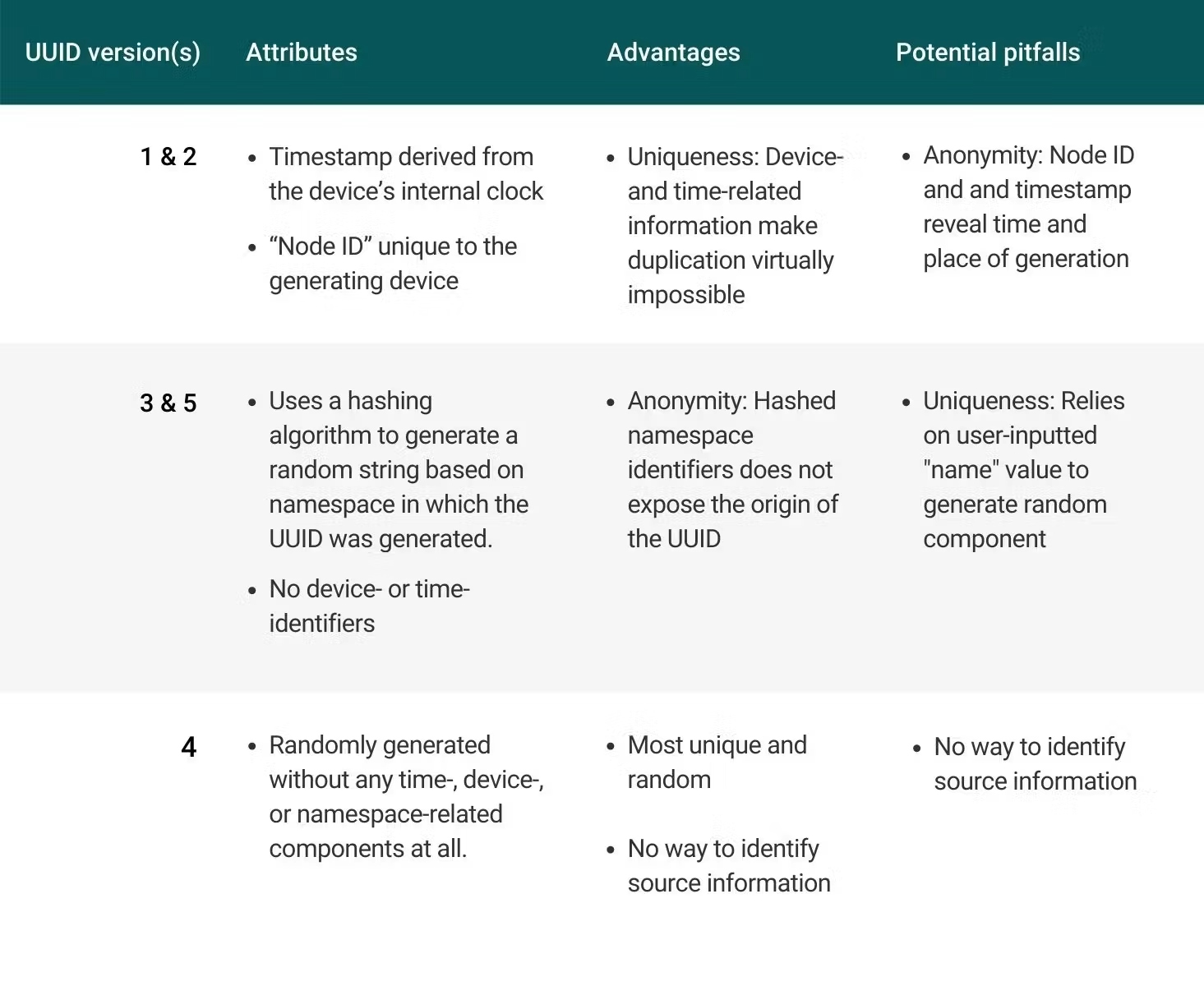
Voici un récapitulatif des attributs, des avantages possibles et des pièges potentiels de chaque version de l'UUID :
Comment générer des UUID dans les applications ?
Bien que vous puissiez être tenté de « créer votre propre » fonction UUID et de l'utiliser dans une application, ce n'est pas la meilleure pratique. Le Groupe de travail sur l'ingénierie Internet—l'organisation qui publie les normes relatives aux UUID——A défini certaines directives concernant le niveau d'unicité que les UUID doivent maintenir. Et bien qu'il soit possible d'écrire une fonction simple dans la langue de votre choix qui renvoie des UUID conformes (dont les critères sont décrits) ici, au cas où cela vous intéresserait), vous ne voudrez probablement pas conserver ce code pour vous assurer que sa sortie reste à la hauteur.
Heureusement, il existe plusieurs bibliothèques bien entretenues que vous pouvez utiliser et qui s'occuperont de cette tâche pour vous. En JavaScript, par exemple, vous pouvez utiliser le paquet uuid npm. Après avoir exécuté npm install uuid, vous pouvez spécifier la version de l'UUID que vous souhaitez utiliser dans les instructions d'importation :
`importer {v1 en tant que uuidv1} depuis 'uuid' ; `
Créer un UUID de version 1 serait alors aussi simple que d'appeler uuidv1 () en tant que fonction, ou en transmettant des options supplémentaires spécifiant les données de nœud et de temps :
const v1options = {
node: [0x01, 0x23, 0x45, 0x67, 0x89, 0xab],
clockseq: 0x1234,
msecs: new Date('2011-11-01').getTime(),
nsecs: 5678,
};
uuidv1(v1options);Dans un environnement Python, UUID library illustré ci-dessus est un outil de secours, bien que de nombreux développeurs aient créé d'autres options pour répondre à des cas d'utilisation spécifiques. À moins que votre application ou base de données ne nécessite une utilisation nuancée des UUID qu'un package populaire ne peut pas gérer, la meilleure pratique consiste à utiliser une bibliothèque bien entretenue et régulièrement mise à jour pour garantir que les technologies cryptographiques sous-jacentes à la création de vos identifiants restent à la pointe de la technologie.
Cas d'utilisation de l'UUID
Les UUID conviennent à une grande variété de cas d'utilisation sur différents types de systèmes, car leurs universel la nature signifie qu'ils peuvent être générés n'importe où au sein d'un réseau. Il n'est donc pas nécessaire de confier cette tâche à un seul nœud du système. Voici quelques exemples courants d'utilisation des UUID dans la nature :
Applications Web
Dans une application Web, les UUID peuvent être générés dans le front-end de l'application sans qu'il soit nécessaire d'appeler un serveur ou une base de données. Les UUID sont donc idéaux pour étiqueter les objets de données liés à la gestion des états, tels que les identifiants d'utilisateur ou de session.
Analysis systems
Tout système d'application tiers qui s'intègre à une application Web ou mobile, tel que des outils de marketing, d'analyse et de publicité, aura probablement besoin de générer des identifiants uniques. Par exemple, une agence de publicité qui souhaite identifier les impressions, les clics et d'autres événements au cours d'une seule session utilisateur peut générer un UUID au début d'une session, puis associer des événements individuels à cet identifiant unique.
Data Bases Systems
Dans les systèmes de bases de données distribuées, les UUID peuvent être très utiles pour diviser de grandes tables et les stocker sur plusieurs serveurs. Chaque partie d'une même table peut recevoir le même UUID, ce qui permet d'identifier les données comme un ensemble unique lors de l'exécution d'opérations de lecture/écriture.
Vous êtes intéressé par le thème de l'identité des utilisateurs et de la gestion de l'identification des données entre systèmes ? Découvrez comment les plateformes de données clients aider les équipes d'ingénierie simplifiez la collecte de données cross-canal, rationalisez la transformation et la diffusion des données et relevez les autres défis techniques de l'écosystème de données moderne.
Remarque : si vous avez besoin de déterminer la probabilité d'une collision UUID, ou si la théorie des probabilités vous apporte simplement de la joie, vous pouvez utiliser Anniversary Problem.



.png)

